ChatGPT may not really need an introduction if you’ve used it. You’ve probably seen that it can often answer questions about code snippets, help summarize documents, write coherent short stories, and the list goes on. Now, it has plenty of limitations and is very capable of making mistakes, but it represents just how far language modeling has come these past few years.
In this article, we’ll specifically cover the training objectives used to develop ChatGPT. The approach follows a similar methodology to instruct GPT, which was released about a year prior. That model was specifically geared towards instruction following. The user provides a single request, and the model outputs a response.ChatGPT extends to more interactive dialogues with back and forth messages where the model can retain and use context from earlier in an exchange. There are three main stages to the training recipe:
- Generative pre-training, where we train a raw language model on text data.
- Supervised fine-tuning, where the model is further trained to mimic ideal chatbot behavior demonstrated by humans.
- And reinforcement learning from human feedback, where human preferences over alternative model outputs will be used to define a reward function for additional training with RL.

In each of these steps, the model is fine-tuned from the results of the step prior. that is, its weights will be initialized to the final weights obtained in the previous stage. We’ll step through these one by one.
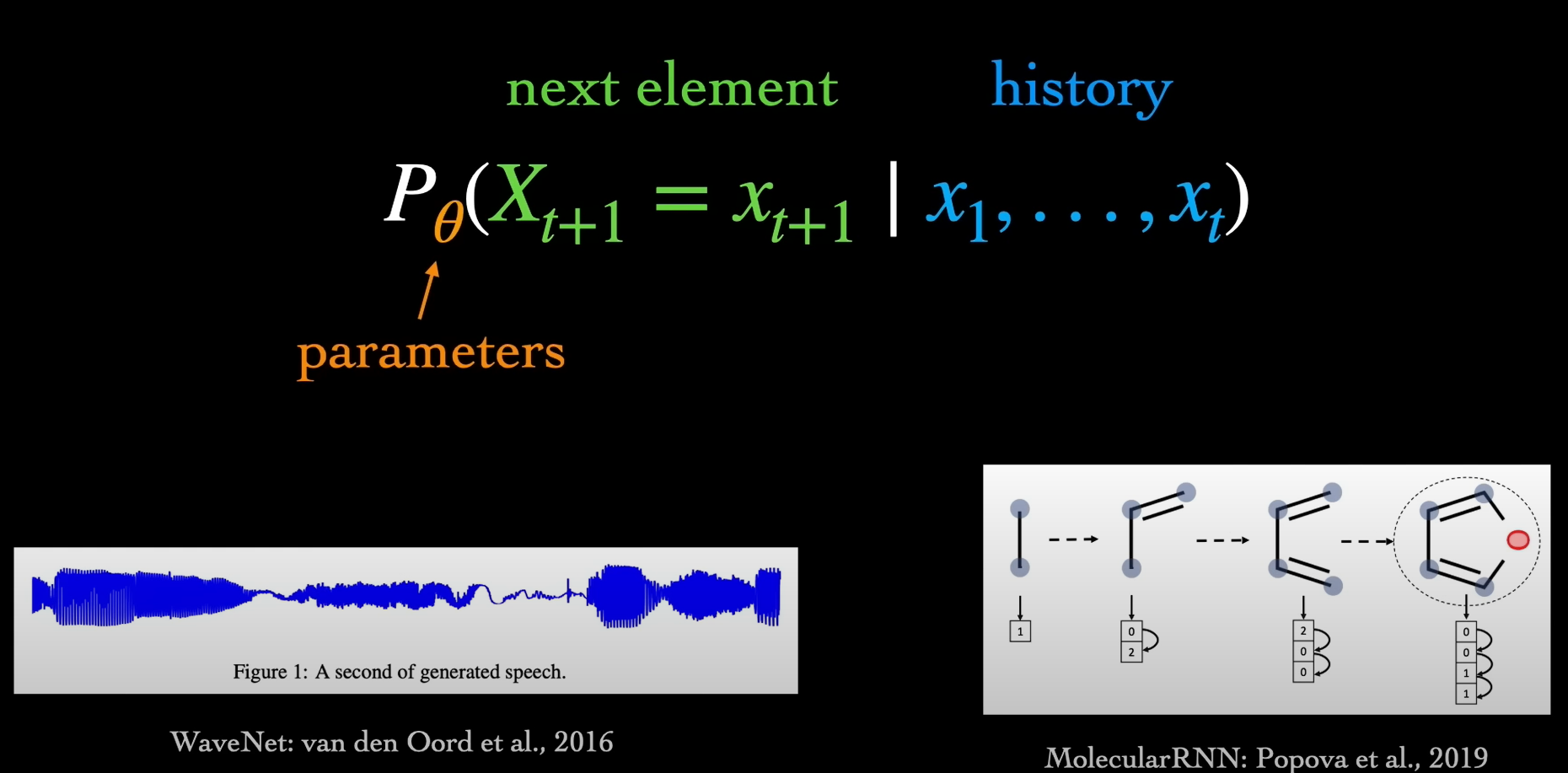
So first, to refresh, what is a language model? Well, it’s basically a special case of an auto regressive sequence model. Given some history of observed variables X1 through XT, a basic sequence model is tasked with predicting XT plus one. During training, we extract sequences from a dataset and adjust the model’s parameters to maximize the probability assigned to the true XT plus ones conditioned on the histories.
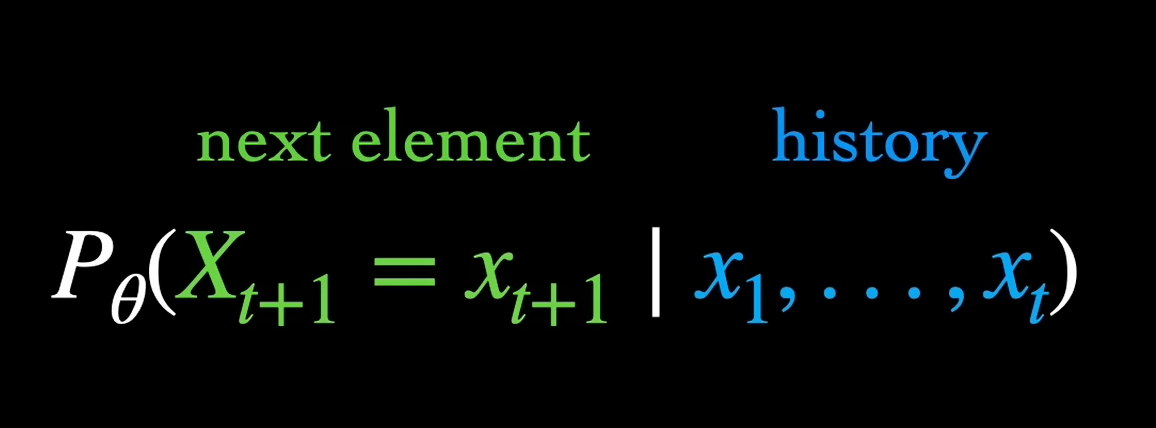
This next step prediction paradigm has been applied across different domains like audio waveforms and molecular graphs. In the case of language models, the individual variables, which we’ll refer to as tokens, can represent words or sub-components of words. For example, given the first four words of the sentence, a language model using word tokens will output a probability distribution over all the words in its vocabulary, indicating how likely each word is to come next, at least according to the model’s estimation.
The vast majority of tokens would receive close to zero probability as they wouldn’t make any sense here, but a few plausible ones will get some non-zero probability mass. Now, even though a language model is simply trained to predict the next token in text data, at inference time, we usually want to not just passively try to predict but actually generate sequences of tokens.
At each step, we can sample a token from the probability distribution output by the model and repeat this process over and over until a special stop token is selected. This setup is agnostic to the specific model architecture used, but typically, modern language models are large transformers consisting of billions of parameters.
Models from the past few years include GPT-3 from OpenAI or BERT from Google. These are trained on massive amounts of text scraped from the internet—chat forms, blogs, books, scripts, academic papers, code—really anything.
The amount of history the models can condition on during inference has a limit, though. For ChatGPT, the underlying language model can attend to about 3,000 words of prior context, so long enough for short conversations but obviously not quite sufficient to output an entire novel.
By pre-training on this large amount of kind of unstructured heterogeneous text data, we allow the model to learn sophisticated probabilistic dependencies between words, sentences, and paragraphs across different use cases of human language.
So why is this generative modeling formulation, this basic language model objective, not enough? Why can’t this alone produce the end behavior we see from ChatGPT? Well, the user wants the model to directly follow instructions or to engage in an informative dialogue. So there’s actually a misalignment between the task implicit in the language modeling objective and the downstream task that the model developers or end-users want the model to perform.
The task represented by the language model pre-training is actually a huge mixture of tasks. The user input is not necessarily enough to disambiguate among these. For example, say a user provides this input: “Explain how the bubble sort algorithm works.” To us, it’s obvious what the user wants the model to do, but the model is only trained to output plausible completions or continuations to pieces of text. So, responding with a sentence like “Explain how the merge sort algorithm works” is not entirely unreasonable.After all, in its training data somewhere, there are documents that just contain lists of questions on different topics like exams.
The task we want the model to perform is actually just a subset of those represented in the data. Now, even without any extra training, we can often get a language model to perform a desired task via prompting. We do this by first conditioning the model on a manually constructed example illustrating the desired behavior. But this is extra work on the part of the user and can be tedious.
In addition to the task being underspecified for a raw language model, there are also subjective preferences that the developers may have regarding other characteristics of the model’s output. For example, they may want the model to refuse to answer queries seeking advice for committing acts of violence or other illicit activities.
When dealing with a probabilistic model, it may be difficult to completely eliminate violations of these specifications, but developers would like to minimize their frequency if possible. So, in the second stage, the model will be fine-tuned a bit with straightforward supervised learning.
Human contractors first conduct conversations where they play both sides—both the human user and the ideal chatbot. These conversations are aggregated into a dataset where each training example consists of a particular conversation history paired with the next response of the human acting as the chatbot.
So, given a particular history, the objective is to maximize the probability the model assigns to the sequence of tokens in the corresponding response. This can be viewed as a typical imitation learning setup, specifically behavior cloning, where we attempt to mimic an expert’s action distribution conditioned on an input state.
So already with this step, this does much better than the raw language model at responding to user requests with less need for prompting, but it still has limitations. There’s a problem of distributional shift when it comes to this type of imitative setting, whether it’s in language or other domains like driving a car or playing a game.
The distribution of states during training of the model is determined by the expert policy, the behavior of the human demonstrator, but at inference time, it’s the model or the agent itself that influenced the distribution of visited states. And in general, the model does not learn the expert’s policy exactly. It may be able to approximate it decently, but a variety of practical factors can limit this approximation, whether it’s insufficient training data, partial observability of the environment, or optimization difficulties.
So, as the model takes actions, it may make mistakes that the human demonstrator was unlikely to, and once such an action takes place, it can lead to a new state that has lower support under the training distribution. This can lead to a compounding error effect; the model may be increasingly prone to errors as these novel states are encountered, where it has less training experience.
It can be shown theoretically that the expected error actually grows quadratically in the length of an episode. In the case of a language model, early mistakes may derail it, causing it to make overconfident assertions or output complete nonsense.
To mitigate this, we need the model or the agent to also act during training, not merely passively observe an expert. One way to do this is to further fine-tune the model with reinforcement learning. Certain RL settings already come with a predefined reward function. If we think about, say, Atari games, then there is an unambiguous reward collected as the game progresses.
Without this, we would typically need to manually construct some reward function, but of course, this is hard in the case of language. Doing well in a conversation is difficult to define precisely. We could have labelers try to assign numerical scores directly, but it may be challenging to calibrate these.
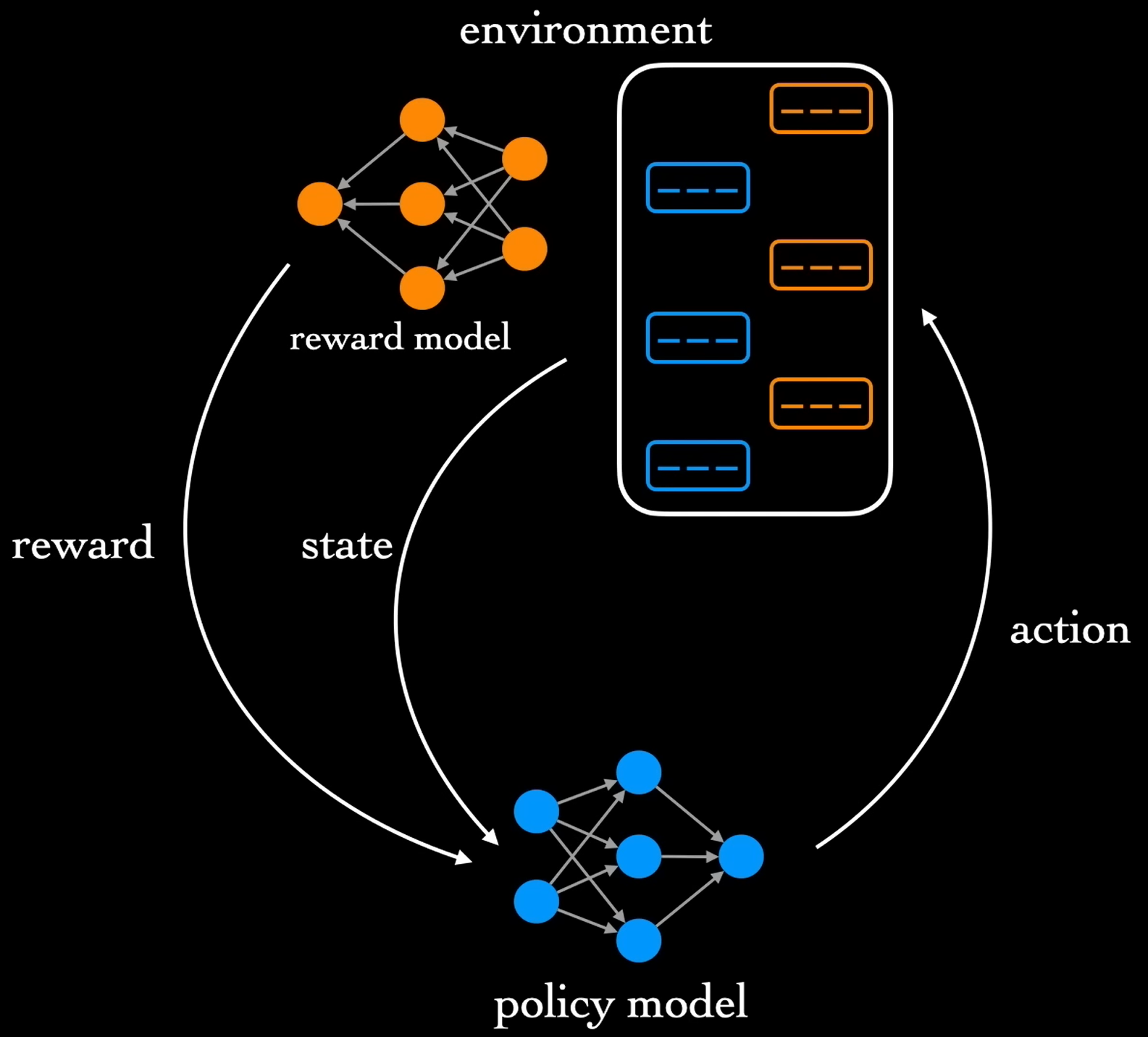
Instead, the developers of ChatGPT establish a reward function based on human preferences. AI trainers first have conversations with the current model. Then, for any given model response, a set of alternative responses are also sampled, and a human labeler ranks them according to most to least preferred. To distill this information into a scalar reward suitable for reinforcement learning, a separate reward model initialized with weights from the supervised model is trained on these rankings.
How well, given a ranking over K outputs for a given input, we can form K choose two training pairs. The reward model will assign a scalar score to each member of a pair, representing logits or unnormalized log probabilities; the greater the score, the greater the probability the model is placing on that response being preferred. Standard cross-entropy is used for the loss, treating the reward model as a binary classifier.
Once trained, the scalar scores can be used as rewards. This will enable more interactive training than the purely supervised setting. During the reinforcement learning stage, our policy model, that is, the chatbot, will be fine-tuned from the final supervised model. It emits actions, its sequences of tokens, when responding to a human in a conversational environment.
Given a particular state, that is, a conversation history, and a corresponding action, the reward model returns the numerical reward. The developers elect to use (proximal policy optimization) or PPO as the reinforcement learning algorithm here. We won’t go into the details of PPO , but this has been a popular choice across different domains.
Now, the learned reward model we’re optimizing against here is a decent approximation to the true objective we care about—the human subjective assessment—but it’s still just an approximation, a proxy objective. In previous work, it’s been shown that there’s a danger of over-optimizing this kind of learned reward where the policies’ performance eventually starts degrading on the true downstream task, even while the reward model scores continue to improve; the policy is exploiting deficiencies in the learned reward model.
This is reminiscent of Goodhart’s law, which states when a measure becomes a target, it ceases to be a good measure. So the authors of the InstructGPT paper describe avoiding this over-optimization by applying an additional term to the PPO objective, penalizing the KL divergence between the RL policy and the policy learned previously from supervised fine-tuning.
The combination of reward model learning and PPO is iterated several times. At each iteration, the updated policy can be used to gather more responses for preference ranking, and a new reward model is trained. Then, the policy is updated through another round of PPO.
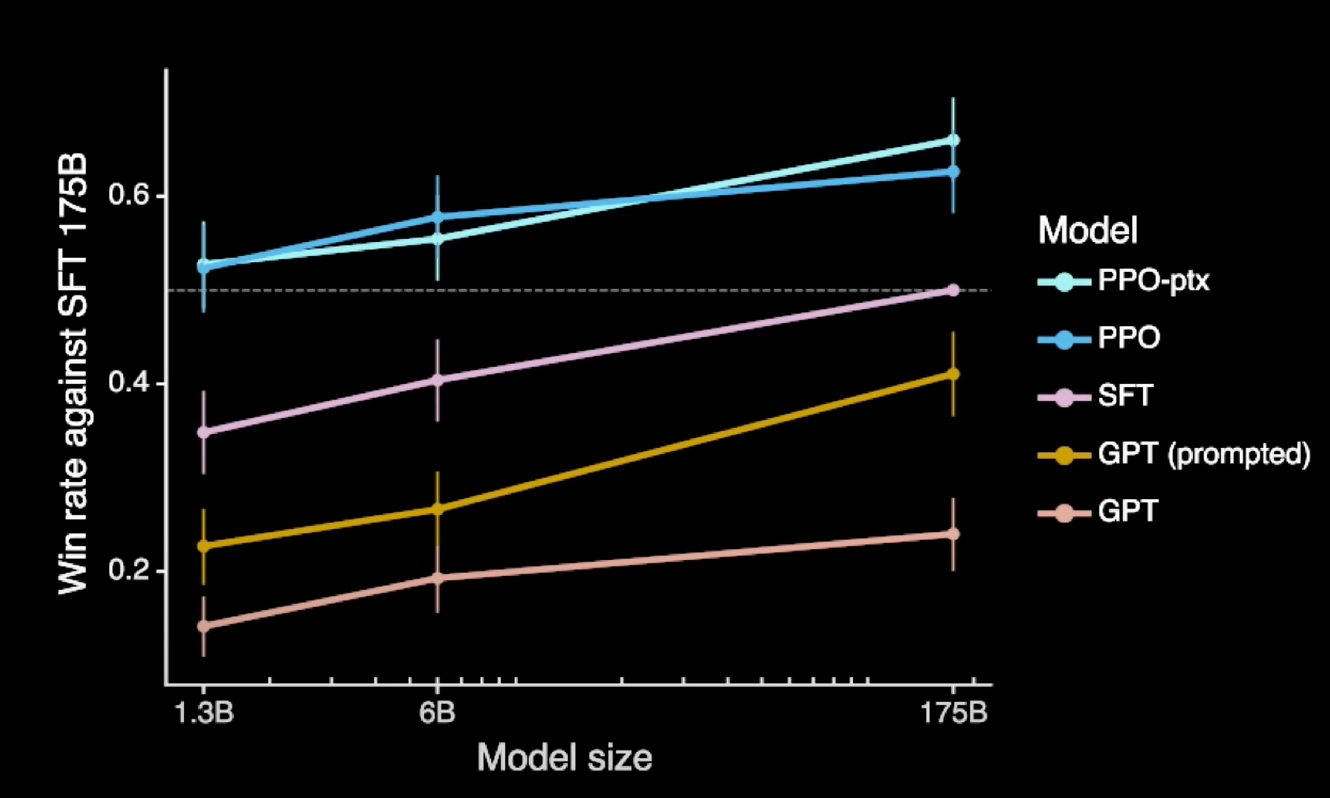
The two fine-tuning steps together, that is, the supervised learning and the reinforcement learning from human feedback, have a dramatic effect on the model’s performance. For InstructGPT, the predecessor model to ChatGPT, evaluation showed that on average, labelers preferred responses from a model with only, quote unquote, “1.3 billion parameters” over the original 175 billion parameter GPT-3 from which it was fine-tuned.
Despite ChatGPT’s legitimately sophisticated capabilities, there is still much room for improvement. It will sometimes spit out inaccurate or completely made up facts and cannot link out to explicit sources. And its behavior is still highly dependent on the specific wording of an input. Even though prompting is far less needed compared to a base language model, some amount of input hacking may still be required depending on the specific behavior desired.
But of course, these are interesting questions to explore from here as new models are developed building on top of this progress.
本文根据https://www.youtube.com/watch?v=VPRSBzXzavo,可以结合视频一起学习,我觉得讲的还不错,就整理了一遍。
本站点维护了一个每日更新的华语youtuber的排行榜,欢迎点击收藏:
留言