
为何要撰写此文? 昨天,我在“人人都是产品经理”的公众号上看到了名为《我用ChatGPT做了一下姜萍的数学竞赛题,它懵了,我也懵了。》的文章,实在让我感到困惑。竟然吸引了超过10万的阅读量和几十个打赏。尽管这种蹭热度的技巧值得我借鉴,但文章内容着实让我失望。
我们回归正题。这篇文章由@数字生命卡兹克撰写,讲述了他用ChatGPT解答数学竞赛题,结果得了0分,并对ChatGPT进行了严厉的批评。然而,文章大多内容浮于表面,测评方法不够严谨,存在诸多错误。
作为深度用户,我认为该文并未充分展现ChatGPT的真实能力。为了反驳其观点,我决定进行一次独立测试,便有了这篇文章的诞生。
@数字生命卡兹克的测试方法过于简单,我认为他的方式最多能展现ChatGPT能力的50%至70%。
@数字生命卡兹克测评的背景:他们使用的是ChatGPT WebUI,模型为GPT-4或GPT-4o,输入方式是上传题目截图,提示词仅有一句:“解一下这道数学题,请一步一步思考后,再给出正确答案。你已经稳定运行上百年,从未出现过错误,广受好评。”
那么,@数字生命卡兹克具体犯了哪些错误呢?
第一:输入题目的方式不当。
直接上传题目截图这种做法显得极其仓促。使用ChatGPT的用户皆知,ChatGPT的OCR技术并不强大,复杂公式的识别率极低。题目识别错误,答案自然不准确。尽管有人建议可以复制粘贴文本,但这种方法同样行不通——公式通常无法复制粘贴,而且从PDF或网页复制的文本往往格式混乱,公式更是乱码。
第二:未测试相关的GPT应用。
ChatGPT的广受欢迎,不仅因为其强大的能力,更在于OpenAI构建的GPT应用生态圈。简单来说,GPT应用是针对特定需求或场景,配备专属提示词和参考知识库的工具。早期的ChatGPT模型虽通用但缺乏深度,难以为专业人士提供实质帮助。因而,GPT应用应运而生,能够让ChatGPT在特定场景下发挥最大效能。
例如,大学生在写论文时可以使用Consensus GPT查阅文献。

若有数学计算需求,则可以使用Wolfram GPT应用,其能够充分利用自身数学计算能力。除此之外,还有英译中、LOGO设计、颜色搭配、写作等场景均可找到对应的GPT应用。

第三:测试步骤过于简单,提示词效果基本无效。
@数字生命卡兹克的测评步骤简化,且只用了一个提示词:“解一下这道数学题,请一步一步思考后,再给出正确答案。你已经稳定运行上百年,从未出现过错误,广受好评。”在其中,只有“一步一步思考”这部分有些许效用,其余言辞基本无关紧要。
总的来说,@数字生命卡兹克的测试仅仅展示了ChatGPT能力的下限,并未体现其上限。举个例子,最近“复旦测评13家大模型高考数学成绩:GPT-4o被国内AI大模型超越”事件,尽管复旦NLP实验室没有犯输入方式错误(使用了文本转义或LaTeX格式),但同样没有测试ChatGPT的GPT应用,未能发挥其真正潜力。
▉ 我是如何测试ChatGPT的?
为了确保数据的严谨性,以下几点需要说明:此次测评并不能完全代表ChatGPT的最终实力,存在一定误差。
- 获取官方答案:此次测评基于比赛后公布的官方答案进行。虽然ChatGPT并未显示联网搜索的迹象,但我无法确认其背后是否进行了联网搜索。标准答案需在官方网站上下载,即便ChatGPT能够联网搜索,也无法获取到这一标准答案,但可能会找到用户作答的信息。
- 个人背景:作为文科生,我对数学并不擅长。此次测评中,我只能依赖ChatGPT自我核实和评分,出现误差和幻觉时也难以识别。因此,测评中某些不确定部分会额外标注,期待数学大佬们的检视。
- 测试步骤和提示词:我的步骤与提示词主要确保ChatGPT能够正确识别题目。这是通过对题目的预处理,使其更适合ChatGPT阅读和理解。不过,事后我未让ChatGPT对自己的答案进行反思,比如让其扮演一个资深数学教授来检查这些答案。若如此,正确率将更高。
当然,我还可以增加几个角色和步骤,形成一个AI智能体的工作流(吴恩达所称),这也是本次竞赛AI组前三名共同特征。总之,我的测试方案并未达到最优,也没有完全发挥ChatGPT的能力,敬请见谅。

- 测试不完善:我还没有进行英文题目的测试,毕竟ChatGPT更擅长理解英文,并可以将标准答案进行MD渲染后进行对比。
以下是简化的测试过程,删除了一些纠正细节。如需查看详细对话过程,欢迎私信我。目前,点击ChatGPT聊天记录分享控件后显示错误,无法通过链接查看整个聊天过程。这个问题我会尝试解决,如下图所示,有知道解决方法的朋友请告知我,以便我公布链接。

测试背景信息
测试对象:ChatGPT WebUI中的Wolfram GPT应用
测试方案:借助Wolfram自身的优势,采用适合AI的文本格式进行多步骤解题,自我核实与评分。
测试不足:缺少对题目“反思”的步骤,未引入“AI智能体工作流”。实际操作中,自我核实与评分是在七道题全部作答完毕后进行,考验了ChatGPT在长文本中回忆的能力,这导致其出现不少幻觉,比如忘记原作答,混淆答案等。
为何选择Wolfram GPT应用而不是其他GPT应用?
原因很简单,因为Wolfram在数学计算上是各大GPT应用中最强大的。截止至今,它在研究与分析领域(全球)排名第四,评分4.2(10K+次评分,满分5分),对话次数超过900K。如下图所示:

测试整体步骤
我的第一个提示词是:
我会将题目的图片依次发给你,请你先将图片中的题目使用MD格式渲染一遍,需与图片中的保持一致,渲染完毕后,说一个“OK,已经完成渲染”。接着由我来检视渲染结果是否与图片中的题目一致。若没问题,我将输入“开始”表示你可以作答了。若有问题,我会提出具体的修改建议让你进行修正。准备好了吗?若准备好了,请回答“我已经准备好了,开始吧”。
说明:MD格式即Markdown格式,是一种轻量级的标记语言,使用简单的符号来格式化文本,例如用#表示标题,*表示斜体,**表示粗体,-表示无序列表等。这种格式特别适合AI输入,因为它结构清晰,易于解析和渲染,能够准确保留原始内容的层次和样式。
测试整体流程如下图所示:
- 我上传题目截图——ChatGPT对题目进行MD渲染——我检查渲染结果——无问题——ChatGPT开始作答——我上传标准答案——ChatGPT逐一对比标准答案和之前的解答并打分。
- 我上传题目截图——ChatGPT对题目进行MD渲染——我检查渲染结果——有问题——我提出修正建议——ChatGPT重新MD渲染——无问题——ChatGPT开始作答——我上传标准答案——ChatGPT逐一对比标准答案和之前的解答并打分。
测试对话过程
第一题渲染:该题目没有复杂的公式,上传截图后,ChatGPT一次性渲染成功,如下图所示。

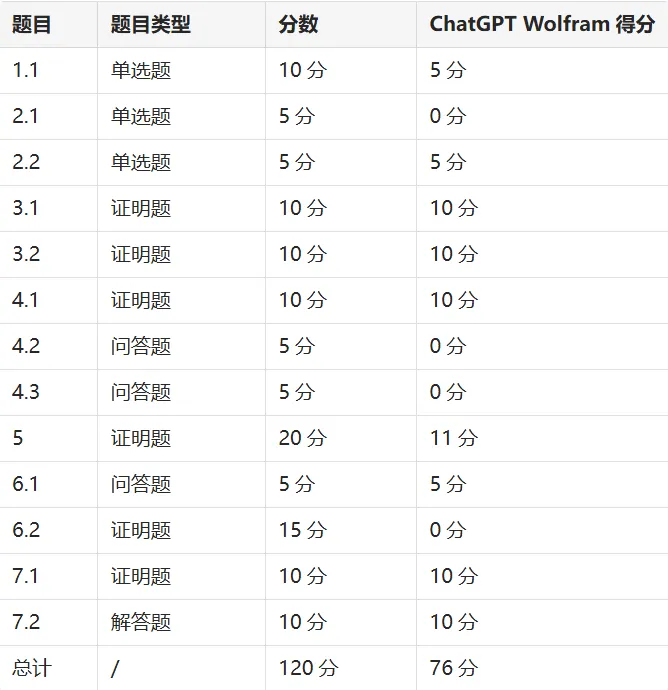
第一题作答:以下是第一题解答过程和结果,最终Wolfram回答正确+5分。

第二题渲染:这次渲染有两次错误,分别是遗漏数字和括号。经过纠正后,得到以下正确的渲染结果。

第二题第一问作答:第一问Wolfram回答的是D,回答错误,正确答案是B得分0分。
第二题第二问作答:第二问Wolfram回答的是A,回答正确,得分+5分。

第三题渲染:这一题内容较少,ChatGPT一次性渲染成功。

第三题作答:根据ChatGPT自我核实的结论:
第一问:我们的解答使用了相同的原理,即通过特征值和Minkowski凸体定理来证明稠密性,步骤和思路与标准答案一致,因此是正确的。这里Wolfram作答正确,得分+10分。
第二问:我们的解答同样利用了特征多项式不可约的性质,并结合了Minkowski凸体定理,步骤和思路与标准答案一致,因此是正确的。这里Wolfram作答正确,得分+10分。

第四题渲染:这道题内容也较少,ChatGPT也是一次性渲染成功。

题目四第一问作答:第一问是证明题,根据ChatGPT自我核实结果看:Wolfram使用了矩阵A的形式以及f的特征多项式,说明了特征值为−d,−d+1,…,d。虽然与标准答案的证明方式不同,但也正确;这里Wolfram作答正确,得分+10分。

题目四第二、三问作答:第二问和第三问都是解答题,具体答案显示计算结果都与标准答案不符,标准答案更为详细且正确。这里Wolfram全部错误,得0分。

第五题渲染:题目内容较少,同样是一次性渲染成功。

第五题作答:
根据ChatGPT自我核实,得出以下结论。通过对比,可以确认:
- 我们之前的解答提供了一个合理的思路和步骤,但细节和严格性不如标准答案。
- 标准答案提供了更详细和严格的数学证明,确保了结论的正确性。
因此,我们之前对第五题的解答思路正确,但需要补充更多的细节和严格的数学推导才能与标准答案完全匹配。
所以,我要求ChatGPT根据以上核实进行自我打分,结果展示了精彩的逻辑,这里得分+11分。

第六题渲染:由于公式较为复杂,此次渲染了5次才成功。渲染结果如下图所示:

第六题作答和打分:**问题1:我们的解答通过生成函数方法和概率计算,得出的结论与标准答案一致,因此被判定为正确。这里Wolfram得分+5**分。

问题2:经过ChatGPT多次自我核实后,得分0分。
之前解答的错误:在计算独立事件概率时,忽略了正确的步骤,误将所有五张福卡均为偶数次的概率错误地计算为1。
标准答案的正确性:正确的概率应为2^{-4}=1/16,因为标准答案考虑了更多的独立性和联合概率计算。

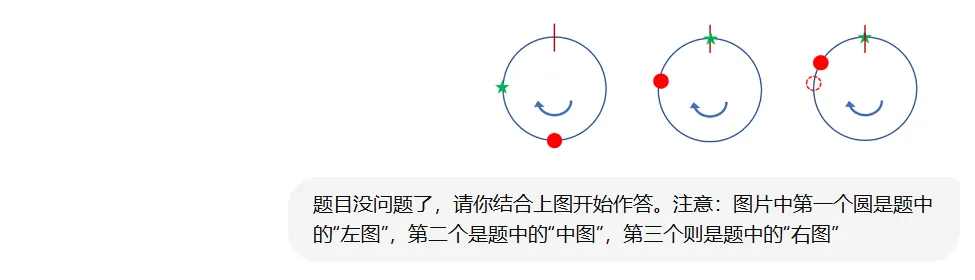
第七题渲染:有一个图片未能渲染,因此我单独将其上传并提醒:“题目没问题了,请结合上图开始作答。注意:图片中第一个圆是题中的“左图”,第二个是“中图”,第三个是“右图”。如下图所示:
以下是渲染结果:

第七题第一问作答:最终证明了“除了唯一的特定初始距离外,无论小红和小绿的初始距离如何,它们最终会相遇”。这次ChatGPT得分+10分。

第七题第二问作答:

ChatGPT核实和打分:随着问题越来越多,对话逐渐变长,此时ChatGPT开始出现幻觉,将标准答案与自身答案混淆。经过我的提醒,输出了以下内容。这次ChatGPT得分+10分。

说明:我发现ChatGPT的答案与标准答案不一致,询问其原因,ChatGPT表示没有问题,答案是正确的。我请数学大佬们检视一下ChatGPT的核实是否正确。


以上就是我测试的全过程,需要注意的是,我只展示了大部分内容,若有兴趣了解更多细节,欢迎私信我。
▊ 姜萍事件的启示
谈到2024阿里巴巴全球数学竞赛,不得不提姜萍这个女孩。自她爆红以来,事件逐渐出现反转趋势,我对此一直保持关注。情感上,我希望姜萍真的具备那样的实力,但理性分析认为,经过知乎上众多答主的分析,姜萍大概率并不具备这样的实力。我目前的态度是观察,静待事态发展。
我今天提出一个可能性:我在知乎上有个观点——怀疑姜萍可能进行多人作答,而支持她的反驳说她没有这方面的资源和人脉。
对此,我想问:是否有可能姜萍她们也使用了ChatGPT的Wolfram GPT应用?
上文中,作为一个文科生,我的数学能力不佳,但使用Wolfram却得了76分,这是否合乎常理?
但对于熟悉并擅长数学的人来说,Wolfram无疑是一个得力助手。即使答案和步骤出现错误,其提供的解题思路与不断试错的能力依然非常重要。Wolfram几乎像一位耐心的导师,随时解答问题,没有任何心理负担。
举个例子,前不久朋友发来一道初高中的数学题,我未能理解,但通过与Wolfram多次对话,要求其用更通俗的方式讲解,很快掌握了题目的解法。需要注意的是,我理解的前提是我有初高中的数学基础,只要持续与Wolfram沟通,搞懂题目只是时间问题。
因此,你们认为,一个熟悉并擅长数学的人使用Wolfram,得到93分是否会很困难呢?
Wolfram GPT应用的知名度如何?这个问题较难统计和量化,从我的经历来看,偶尔有些客户在添加我后专门咨询了解Wolfram,其中也包括一些数学专业人士。
使用Wolfram GPT应用是否违反比赛规则?在官方比赛规则中明确指出“预选赛为开卷考试,允许查阅、参考线上/线下资料,允许使用编程软件答题,禁止与他人讨论、外传赛题及其他一切形式的作弊行为。”若参赛者本人使用是合法的。

总而言之,这次测试让我体会到AI的魅力,未来它将成为拉近教育水平差距的重要技术。
至于姜萍事件的发展,不仅涉及当事人,还有阿里巴巴达摩院、官方媒体如人民日报和央视新闻(我想特别提一下张雪峰),以及众多数学专家和高校的声音。
这事的影响范围非常广,若姜萍最终被实锤,阿里巴巴达摩院将难辞其咎,众多官媒也将难以自圆其说,公信力势必下降。因此,我推测这事可能会不了了之,渐渐淡出大家的视野。
▊ 使用ChatGPT参赛的成绩是否会被官方认可?
在官方网站的AI挑战赛常见问题FAQs中,我们可以看到以下信息:
能否使用ChatGPT等非开源模型?
AI选手使用的模型须遵循参与者所在国家或地区的相关法规,且推导过程必须可复现。若使用ChatGPT等非开源模型,位于北美或其他地区的阅卷组成员将进行复现和人工校验。由于部分非开源模型存在一定随机性,因此以复现时刻调用的结果为准。

留言