
任务一:超参数调优与模型评估
- 对
lrn("regr.ranger")模型在tsk("mtcars")数据集上的mtry、sample.fraction和num.trees超参数进行调优。采用简单的随机搜索方法进行 50 次评估,利用三折交叉验证和均方根误差(RMSE)来评估模型性能。通过边际效应图可视化每个超参数对模型性能的影响,展现单个超参数与交叉验证均方误差(MSE)之间的关系。
调优 lrn("regr.ranger") 模型时,使用随机搜索方法对 mtry、sample.fraction 和 num.trees 进行参数选择,确保能够有效评估模型性能。
以下代码片段展示了如何使用 mlr3 框架进行超参数调优的具体步骤。接下来对每行代码进行详细解析,尤其是在建模过程中需要关注的 instance 和调优器的用法与区别。
set.seed(1234)
- 设置随机数种子以确保结果可复现。
mytask1 <- tsk("mtcars")
- 创建任务
mytask1,使用mtcars数据集,该数据集用于回归分析(预测连续变量,如汽车的燃油效率)。
learner1 <- lrn("regr.ranger", mtry = to_tune(1, 10), sample.fraction = to_tune(0.5, 1), num.trees = to_tune(100, 500))
- 定义回归模型
learner1,使用随机森林回归器regr.ranger(Ranger 库)。 - 设置
mtry、sample.fraction和num.trees作为超参数,并定义其调优范围:mtry: 在每棵树的节点分裂时随机选择的变量数量,调整范围为 1 到 10。sample.fraction: 每棵树的样本比例,调整范围为 0.5 到 1(即从 50% 到 100% 的样本用于训练每棵树)。num.trees: 森林中的树木数量,调整范围为 100 到 500。
learner1$param_set
- 显示
learner1的参数集合,包含所有可调节参数及其当前值和调优范围。
instance <- ti( learner = learner1, task = mytask1, resampling = rsmp("cv", folds = 3), measure = msr("regr.rmse"), terminator = trm("evals", n_evals = 50) )
- 创建调优实例
instance,定义模型调优的各个方面:learner = learner1: 要调优的学习器是learner1(随机森林)。task = mytask1: 任务是回归任务mtcars数据集。resampling = rsmp("cv", folds = 3): 使用三折交叉验证评估模型性能。measure = msr("regr.rmse"): 评估指标是回归均方根误差(RMSE),目标是最小化此值。terminator = trm("evals", n_evals = 50): 定义调优的停止条件,最多进行 50 次评估。
tuner <- tnr("random_search", batch_size = 10)
- 定义调优器
tuner,采用随机搜索策略(random_search),每次评估 10 个超参数组合。
tuner$optimize(instance)
- 运行调优过程,通过随机搜索优化
instance中的模型超参数。根据设置的停止条件,最多进行 50 次评估。
as.data.table(instance$archive)
- 以数据表形式显示调优历史结果,包含每次调优的超参数组合及对应的评估性能(如 RMSE)。
instance$result

- 返回调优的最终结果,包含最佳超参数组合及其性能。
autoplot(instance, type = "incumbent")
- 绘制调优过程中最佳模型(
incumbent)的性能变化图,展示当前最佳模型在调优过程中的演变。
autoplot(instance, type = "marginal")
- 绘制每个单一超参数的边际效应图(
marginal),展示超参数值如何影响模型的性能(例如 RMSE)。
注意事项:
- 任务与学习器选择:任务 (
task) 和学习器 (learner) 的选择必须与问题相符。这里使用regr.ranger回归器进行回归任务,符合mtcars数据的性质。 - 超参数调优范围:调优范围选择要合理,既不能过宽(耗时较长,且可能导致过拟合),也不能过窄(可能错失最佳参数)。此处
mtry、sample.fraction和num.trees的范围定义适中。 - 交叉验证:使用交叉验证避免过拟合,确保模型的泛化能力。三折交叉验证是合理的选择,折数可根据数据集大小进行调整。
- 终止条件:调优过程需设定适当的终止条件。这里通过
n_evals = 50限制最多 50 次评估,避免因搜索空间过大导致的时间过长问题。
instance 的定义
instance 是调优实例,包含整个调优过程所需的所有信息和设置。它定义了要优化的模型、数据集、评估指标、重采样方法、超参数搜索空间和终止条件。instance 是模型调优过程中的核心对象。
ti() 与 tnr() 的用法与区别
ti()(TuningInstance): 用于定义调优实例,包含学习器、任务、超参数搜索空间、评估指标和终止条件等。它负责收集调优过程中所有的重要信息,并最终输出调优结果。tnr()(Tuner): 调优器,用于执行调优过程的具体方法。不同的调优器(如random_search、grid_search)使用不同的搜索策略来优化超参数组合。tnr()定义了调优策略,主要职责是探索调优实例中的搜索空间。
简而言之,ti() 定义了调优任务的框架,而 tnr() 是实际执行调优过程的工具。
任务二:利用嵌套重抽样评估模型性能
- 使用嵌套重抽样评估在第一任务中创建的模型的性能。内部重抽样采用留出法,外部重抽样采用三折交叉验证。
以下是使用嵌套重抽样的方法:
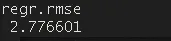
set.seed(1234) # 设置随机数种子,确保结果可复现。task = tsk("mtcars") # 创建任务 `task`,数据集为 `mtcars`,任务类型是回归。learner = lrn("regr.ranger", mtry = to_tune(1, 10), # 定义超参数 `mtry` 的调优范围,从 1 到 10。 sample.fraction = to_tune(0.5, 1), # 定义超参数 `sample.fraction` 的调优范围,从 0.5 到 1。 num.trees = to_tune(100, 500) # 定义超参数 `num.trees` 的调优范围,从 100 到 500。)at = auto_tuner( tuner = tnr("random_search", batch_size = 50), # 使用随机搜索作为调优器,每次批量评估 50 组超参数组合。 learner = learner, # 使用之前定义的学习器 `learner`。 resampling = rsmp("holdout"), # 使用持出法(Holdout)进行模型评估。 measure = msr("regr.rmse"), # 评估指标为均方根误差(RMSE),目标是最小化该值。 terminator = trm("evals", n_evals = 50) # 设置调优的终止条件为最多评估 50 次超参数组合。)rr = resample(task, at, rsmp("cv", folds = 3)) # 使用三折交叉验证对 `auto_tuner` 实例 `at` 进行重采样,评估模型性能。rr$aggregate(msr("regr.rmse")) # 聚合交叉验证的结果,计算均方根误差(RMSE)的平均值,得到模型的最终评估指标。
任务三:XGBoost模型与逻辑回归的性能比较
- 对比调优后的 XGBoost 模型与未经调优的逻辑回归模型,确定哪一个模型具有最佳的 Brier 评分。使用
mlr3tuningspaces和嵌套重抽样,选择适当的内部和外部重采样策略,以平衡计算效率与结果的稳定性。
以下是实现步骤:
set.seed(1234) # 设置随机数种子,确保结果可复现。mytask2 <- tsk("sonar") # 创建任务 `mytask2`,数据集为 `sonar`,任务类型是分类。# 定义逻辑回归模型lrn_log_reg <- lrn("classif.log_reg", predict_type = "prob") # 创建逻辑回归学习器并指定预测类型为概率。# 定义 XGBoost 模型lrn_xgboost = lrn("classif.xgboost", predict_type = "prob") # 创建 XGBoost 分类学习器并指定预测类型为概率。# 获取 XGBoost 的默认调优空间lrn_xgboostspace = lts("regr.xgboost.default") # 获取 XGBoost 回归模型的默认调优空间(可能需要调整为分类任务的调优空间)。# 查看 XGBoost 调优空间的详细信息,确认超参数范围。lrn_xgboostspace # 定义 XGBoost 自动调优器at_xgboost <- auto_tuner( tuner = tnr("random_search", batch_size = 20), # 使用随机搜索作为调优器,每次批量评估 20 组超参数组合。 learner = lrn_xgboost, # 使用之前定义的 XGBoost 学习器。 resampling = rsmp("cv", folds = 3), # 使用三折交叉验证进行模型评估。 measure = msr("classif.bbrier"), # 评估指标为 Brier 评分(适用于分类问题),目标是最小化该值。 search_space = lrn_xgboostspace, # 设置超参数调优空间。 terminator = trm("evals", n_evals = 50) # 设置调优终止条件为最多评估 50 次超参数组合。)# 定义基准测试设计design <- benchmark_grid( tasks = mytask2, # 使用 `mytask2` 任务。 learners = list(lrn_log_reg, at_xgboost), # 列出要测试的学习器,包括逻辑回归和自动调优后的 XGBoost。 resamplings = rsmp("cv", folds = 5) # 使用五折交叉验证进行评估。)bmr <- benchmark(design) # 执行基准测试,根据设计对学习器进行评估。bmr$aggregate(msr("classif.bbrier")) # 聚合基准测试结果,计算 Brier 评分的平均值,评估模型性能。autoplot(bmr, type = "roc") # 绘制 ROC 曲线图,比较不同模型的分类性能。
留言